Generating Gamma Random Variable in CUDA in Parallel
Recently, I had to write a random variable generator for Gamma Distributions. I couldn’t find one for Gamma distribution in cuRAND API of CUDA version 8.0. After googling about how to generate a gamma random variable I found out two rejection methods for doing so in its Wikipedia page under the section “Generating gamma-distributed random variables”. Out of these two methods “Marsaglia and Tsang’s Method” which is a transformation-rejection based method is the one used in many other scientific softwares like Matlab and GSL. The I also found the original paper here. If you want a detailed description of the transformation-rejection based method go through it. Here is a nice blog post about the same.
Let’s first setup Visual Studio. I am using VS2013 Ultimate on my machine which has a i7 processor and a gtx960m graphics card. In Visual Studio create a new “Cuda Project”. Remove the example code and keep only the main function.

Now let’s add the code for host and device memory required. We will also have to create the cudaState variables to be able to generate random numbers in parallel. We will assign a unique cudaState variable to each thread. curand_init function is used to create these state variables. Quoting from the cuRAND API Documentation,
The curand_init() function sets up an initial state allocated by the caller using the given seed, sequence number, and offset within the sequence. Different seeds are guaranteed to produce different starting states and different sequences. The same seed always produces the same state and the same sequence. The state set up will be the state after (267 ⋅ sequence + offset) calls to curand() from the seed state.
…
For the highest quality parallel pseudorandom number generation, each experiment should be assigned a unique seed. Within an experiment, each thread of computation should be assigned a unique sequence number. If an experiment spans multiple kernel launches, it is recommended that threads between kernel launches be given the same seed, and sequence numbers be assigned in a monotonically increasing way. If the same configuration of threads is launched, random state can be preserved in global memory between launches to avoid state setup time.
#include "device_launch_parameters.h"
#include <curand.h>
#include <curand_kernel.h>
__global__ void setup(curandState_t *d_states)
{
int id = threadIdx.x;
curand_init(345, id, 0, &d_states[id]);
}
int main(){
int numThreads = 100;
int length = 100; // Sample generated per thread
// Allocate memory on host side
double* h_samples = new double[numThreads*length];
// Allocate device memory
double* d_samples;
int bytes = numThreads*length*sizeof(double);
cudaMalloc(&d_samples, bytes);
// Create state variables
curandState_t* d_states;
cudaMalloc(&d_states, sizeof(curandState_t)*numThreads);
setup<<<1, numThreads>>>(d_states);
}As described earlier we would need two samples, from a uniform and a normal distributions respectively. We would use CUDA api functions curand_normal and curand_uniform for this purpose. We now need to pass the curandState variables, we created earlier, to these functions. The function prototypes are:
/*
This function returns a sequence of pseudorandom floats uniformly distributed
between 0.0 and 1.0. It may return from 0.0 to 1.0, where 1.0 is included and
0.0 is excluded. Distribution functions may use any number of unsigned integer
values from a basic generator. The number of values consumed is not guaranteed
to be fixed.
*/
__device__ float curand_uniform (curandState_t *state)
/*
This function returns a single normally distributed float with mean 0.0 and
standard deviation 1.0. This result can be scaled and shifted to produce
normally distributed values with any mean and standard deviation.
*/
__device__ float curand_normal (curandState_t *state)Now let’s write the function that would generate a gamma random variable. Note that I have used the double2 (a 2-by-1 double vector) data structure for passing the alpha and beta parameters.
/*
Gamma Random Variable generator
Marsaglia and Tsang’s Method
*/
__device__ void gamrnd_d(double* x, double2* params, \
curandState_t* d_localstates)
{
double alpha = params->x;
double beta = params->y;
if (alpha >= 1){
// Be careful the change in localState variable needs
// to be reflected back to d_localStates
curandState_t localState = *d_localstates;
double d = alpha - 1 / 3.0, c = 1 / sqrt(9 * d);
do{
double z = curand_normal(&localState);
double u = curand_uniform(&localState);
double v = pow((double) 1.0f + c*z, (double) 3.0f);
double extra = 0;
if (z > -1 / c && log(u) < (z*z / 2 + d - d*v + d*log(v))){
*x = d*v / beta;
*d_localstates = localState;
return;
}
} while (true);
}
else{
double r;
params->x += 1;
gamrnd_d(&r, params, d_localstates);
curandState_t localState = *d_localstates;
double u = curand_uniform(&localState);
*x = r*pow((double)u, (double)1 / alpha);
params->x -= 1;
return;
}
}Here’s the final code for generating gamma random variables on gpu and printing them.
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <curand.h>
#include <curand_kernel.h>
#include <iostream>
#include <fstream>
using namespace std;
__global__ void setup(curandState_t *d_states)
{
int id = threadIdx.x;
curand_init(345, id, 0, &d_states[id]);
}
__device__ void gamrnd_d(double* x, double2* params, \
curandState_t* d_localstates)
{
double alpha = params->x;
double beta = params->y;
if (alpha >= 1){
curandState_t localState = *d_localstates; // Be careful the change in localState variable needs to be reflected back to d_localStates
double d = alpha - 1 / 3.0, c = 1 / sqrt(9 * d);
do{
double z = curand_normal(&localState);
double u = curand_uniform(&localState);
double v = pow((double) 1.0f + c*z, (double) 3.0f);
double extra = 0;
if (z > -1 / c && log(u) < (z*z / 2 + d - d*v + d*log(v))){
*x = d*v / beta;
*d_localstates = localState;
return;
}
} while (true);
}
else{
double r;
params->x += 1;
gamrnd_d(&r, params, d_localstates);
curandState_t localState = *d_localstates;
double u = curand_uniform(&localState);
*x = r*pow((double)u, (double)1 / alpha);
params->x -= 1;
return;
}
}
// Each thread will fill up individual columns of the matrix
__global__ void generateGamma_d(double* mat, double2* params, int rows, int cols, curandState_t* d_localstates)
{
// calculate column id to be filled by this thread
int c = blockIdx.x*blockDim.x + threadIdx.x;
if (c < cols){
for (int r = 0; r < rows; r++)
{
gamrnd_d(&mat[c*rows + r], params, &d_localstates[c]);
}
}
}
int main(){
int rows = 100;
int cols = 100;
int numThreads = cols;
int length = rows; // Sample generated per thread
// Allocate memory on host side
double* h_mat = new double[rows*cols];
// Allocate device memory
double* d_mat;
int bytes = numThreads*length*sizeof(double);
cudaMalloc(&d_mat, bytes);
// Create state variables for each thread
curandState_t* d_states;
cudaMalloc(&d_states, sizeof(curandState_t)*numThreads);
setup<<<1, numThreads>>>(d_states);
unsigned int threadsPerBlock = 32;
unsigned int numBlocks = ceil((double)cols / threadsPerBlock);
double2 h_params{ 2, 0.8 };
double2 *d_params;
cudaMalloc(&d_params, sizeof(double2));
cudaMemcpy(d_params, &h_params, sizeof(double2), cudaMemcpyHostToDevice);
generateGamma_d<<<numBlocks, threadsPerBlock>>>(d_mat, d_params, rows, cols, d_states);
cudaMemcpy(h_mat, d_mat, bytes, cudaMemcpyDeviceToHost);
ofstream outfstream("outG.csv");
for (int i = 0; i < rows; i++)
{
for (int j = 0; j < cols; j++)
{
//cout << h_mat[j*rows + i] << ((j<cols-1)?",":"");
outfstream << h_mat[j*rows + i] << ",";
}
//cout << endl;
outfstream << endl;
}
cudaFree(d_mat);
cudaFree(d_states);
cudaFree(d_params);
free(h_mat);
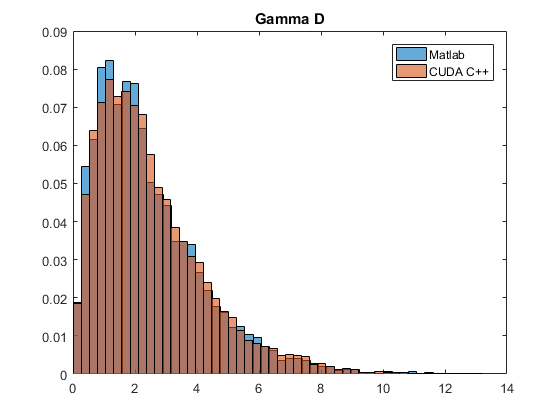
}Now we will verify the implementation by plotting a histogram of the samples generated in MATLAB and comparing it against histogram of samples generated inside MATLAB. The code for verifying and the histogram plots are given below. Check in the main function of the code above, we dumped the samples created to a csv file, gamout.csv; we would need that file here. Copy that file to the current working directory of MATLAB so that it can load the samples from the file to an array.
clear
close all
t = 6400;
ss = gamrnd(2*ones(t, 1), 1/0.8*ones(t, 1));
bins = 0:max(ss)/50:max(ss);
[counts] = histcounts(ss, bins);
histogram(ss, 50, 'Normalization','probability');
filename = 'D:UsersBishal SantraDocumentsVisual Studio 2013ProjectsGamRV_TutGamRV_TutoutG.csv';
delimiter = ',';
formatSpec = '%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%f%[^nr]';
fileID = fopen(filename,'r');
dataArray = textscan(fileID, formatSpec, 'Delimiter', delimiter, 'EmptyValue' ,NaN, 'ReturnOnError', false);
fclose(fileID);
gsamples = [dataArray{1:end-1}];
gsamples = gsamples(:);
clearvars filename delimiter formatSpec fileID dataArray ans;
hold on
histogram(gsamples, bins, 'Normalization','probability');
hold off
legend('Matlab', 'CUDA C++')
title('Gamma D');